Institut für Informatik
Lehr- und Forschungseinheit für Datenbanksysteme
Institute for Computer Science
Database and Information Systems
|
|
Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme |
University of Munich Institute for Computer Science Database and Information Systems |

Indexing high-dimensional data spaces is an emerging research domain. It gains increasing importance by the need to support modern applications by powerful search tools. In the so-called non-standard applications of database systems such as multimedia, CAD, molecular biology, medical imaging, time series processing and many others, similarity search in large data sets is required as a basic functionality.
A technique widely applied for similarity search is the so-called feature transformation, where important properties of the database objects are transformed into points of a multidimensional vector space, the so-called feature vectors. Thus, similarity queries are naturally translated into neighborhood queries in the feature space. In order to achieve a high performance in query processing, multidimensional index structures are used to manage the feature vectors. Unfortunately, multidimensional index structures deteriorate in performance when the dimension of the data space increases, because they are primarily designed for low-dimensional data spaces and due to a bunch of effects usually called the ‘curse of dimensionality’.
Therefore, the general goal of this project is the improvement of the efficiency of index-based query processing in high-dimensional data spaces.
High-Dimensional Access Methods
Most index structures for query processing in high-dimensional data spaces are based on the principle of the R-tree: A balanced tree where each node corresponds to a page of the background memory and to a region of the data space. In contrast to typical 2D indexes such as the R*-tree, these methods cope with problems of high-dimensional data spaces. The X-tree avoids overlap by the concept of supernodes. The pyramid technique and space-filling curves map points into one-dimensional values. The IQ-tree compresses the data to improve query processing.
Parallel and Distributed Index Structures
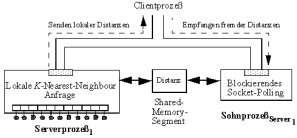
A popular method for improving the query performance of access methods is to introduce parallelism. The main goals of such a parallel or distributed system are short response times and high throughput. There are several aspects which must be carefully considered: How should the data be distributed among the participating sites. How should the query processor work? What is a reasonable architecture? An example for a recently designed parallel access method is the PX-tree (Parallel X-tree). This technique is constructed for both, short response times and high query throughput. Other approaches are the MDX-tree (Multi-Disc X-tree) and the efficient parallel scanning of flat data files when the dimensionality is ultra high.
Cost Models and Index Optimization
One way to cope with performance deteriorations originating from the 'curse of dimensionality' is to construct a cost model for query processing in high-dimensional data spaces and to use the cost model for a careful optimization of various parameters of an index. Examples of suitable parameters are the page size, the dimension assignment or the data space quantization. Our cost models consider effects in high-dimensional data spaces and correlations which are inherent to data from real-world applications.
Efficient Search Algorithms
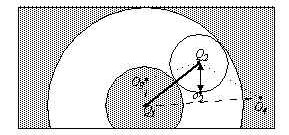
Despite the architecture of an access method, there are various other possibilities to improve the query performance. Among those is the optimization of algorithms, i.e., to transform algorithms such that parts of the query cost can be avoided. One instance is the so-called multiple similarity queries approach. The main idea is that algorithms do not initiate one query after another, but instead initiate a set of queries. In order to bundle queries in query sets, the underlying algorithms have to be modified. The benefit of this transformation is a significant reduction of disk operations. Additional performance improvements can be achieved by applying the triangle inequality in order to save expensive CPU operations. Other examples of optimization approaches we investigated are the use of space filling curves, clever page scheduling techniques and exploiting similarity joins for efficiently mining clusters.
List of papers
Bei Problemen oder Vorschlägen wenden Sie sich bitte an:
wwwmaster@dbs.informatik.uni-muenchen.de
Last Modified: