Institut für Informatik, LFE Datenbanksysteme
Prof. Dr. Hans-Peter Kriegel
Institute for Computer Science
Database and Information Systems
|
|
Ludwig-Maximilians-Universität München Institut für Informatik, LFE Datenbanksysteme Prof. Dr. Hans-Peter Kriegel |
University of Munich Institute for Computer Science Database and Information Systems |
 |
Projekt- und Diplomarbeiten: Clustering und Outlier Detection |
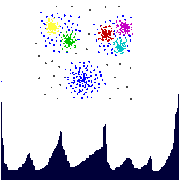
Cluster Analyse ist ein wichtiger Teilbereich des Data Mining. Sie kann entweder als eigenstädige Methode verwendet werden, um neue Einsichten in den Datensatz zu gewinnen, z.B. um das Potential anderer Datenanalyse oder -Verarbeitungsschritte zu evaluieren, oder als ein Vorverarbeitungsschritt für andere Data Mining Verfahren angewendet werden, die auf den entdeckten Clustern arbeiten. Dichtebasierte Verfahren wenden ein lokales Cluster Kriterium an. Cluster sind definiert als Bereiche im Datenraum, in denen die Objekte dicht beieinander liegen, und die durch Gebiete geringer Dichte voneinander getrennt sind (sog. Rauschen). Diese dichten Regionen oder Cluster können beliebig geformt sein und die Datenobjekte in ihnen können beliebig verteilt sein.
Für andere KDD Anwendung, z.B. das Entdecken krimineller Handlungen im E-Commerce, ist es wichtiger, Ausreißer (Outlier), d.h. seltene Beobeachtungen, zu finden.
Ausführlichere Informationen gibt es auf unserer Projektseite.
Werkzeuge
Programmiersprachen: Java, Perl, C, C++ Datenbanksystem: Oracle8i Schnittstellen: JDBC, SQLJ, Java Stored Procedures Visualisierung: Java, Java3D Kontakt
In diesem Projekt sind laufend Projekt- und Diplomarbeiten zu vergeben. Interessierte Studentinnen und Studenten melden sich bitte bei:
- Dr. Jörg Sander, Zi. E 1.07, Oettingenstr. 67, Tel. 2178-2226
- Markus Breunig, Zi. E 1.04, Oettingenstr. 67, Tel. 2178-2225
Bisherige Arbeiten
- Florian Beil:
Web Document Clustering (PA, in Bearbeitung)- Egon Gruber:
Optimierung von Cluster Beschreibungen mittels Genetischer Algorithmen (PA, abgebrochen)- Christian Pooch:
Inkrementelles OPTICS (DA, abgeschlossen im Januar 2001)- Klaus Schneidenwind:
Datenkompression mittels BIRCH in Java (PA, abgeschlossen am 15.10.2000)- Peer Kröger:
Hochrechnen eines gesampelten OPTICS Clusterings auf die Gesamtemenge der Daten (PA, abgeschlossen am 24.07.2000)- Ekkehard Krämer:
BIRCH als Preprocessing Step für OPTICS (PA, abgeschlossen am 17.02.2000)
Homepages:DBS
Markus Breunig (breunig@informatik.uni-muenchen.de), 15.07.99