|
Das Verfahren wurde in Java implementiert und getestet.
Es wurde nur die nn-Klassifikation verwendet.
Dabei wurde ein enormer Speed-Up gegenüber dem herkömmlichen
OPTICS erzielt.
Auch relativ komplizierte Strukturen konnten bei kleinen
Sample-Größen (z.B. 100 Punkten) bereits im
Reachability-Plot des Samples erkannt werden.
Die Klassifikation ist dennoch als Nachbereitung sinnvoll, da es sein
kann, dass es im Sample-Plot zu Stauchungen und/oder Streckungen der
Cluster kommen kann (was am Sampling selber liegt, da es vorkommen
kann, dass aus einem Cluster mehrere Punkte dem Anteil entsprechend
ausgewählt werden, als bei einem anderen).
Ausserdem sind die Punkte, die nicht ins Sample gewählt wurden,
keinem Cluster zuordbar.
Diesen Informationsverlust kann die Klassifikation ausmerzen.
Durch das Ausgleichen der Stauchungen und/oder Streckungen des
Sample-Plots kann man anhand des Klassifikations-Plots auf die
tatsächliche Größe der Cluster schließen.
Auch kann jeder Punkt aus der ursprünglichen Menge einem Cluster
zugeordnet werden.
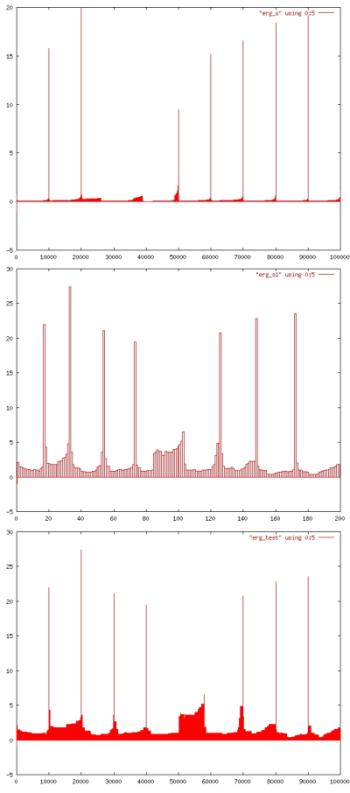
Die Graphik rechts zeigt eines der Ergebnisse mit einem zwei
dimensionalen Datensatz bestehend aus 100 000 Punkten. Der Sample-Plot
(mitte) zeigt im Vergleich zum original OPTICS-Plot (oben) deutlich
Stauchungen und Streckungen (z.B. zweiter und letzter Cluster), die im
Plot nach der Klassifikation (unten) wieder ausgeglichen sind.
Das Verfahren ist besonders bei großen Datensätzen, die
eine deutliche Cluster-Struktur aufweisen, geeignet, um die Laufzeit
der Analyse auf ein erträgliches Maß zu verringern.
Dagegen wurden schlechte Ergebnisse bei Real-Datensätzen mit sehr
wenig Struktur verbucht.
Extrem kleine Cluster gehen in kleinen Sample-Mengen evtl. verloren.
|
|

