Institut für Informatik
Lehr- und Forschungseinheit für Datenbanksysteme
Institute for Computer Science
Database and Information Systems
| Ludwig-Maximilians-Universität
München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme |
University
of Munich Institute for Computer Science Database and Information Systems |
In recent years the growth of the World Wide Web exceeded all expectations. Today there are several billions of HTML documents, pictures and other multimedia files available via internet and the number is still rising. But considering the impressive variety of the web, retrieving interesting content has become a very difficult task. Web Content Mining uses the ideas and principles of data mining and knowledge discovery to screen more specific data. The use of the Web as a provider of information is unfortunately more complex than working with static databases. Because of its very dynamic nature and its vast number of documents, there is a need for new solutions that are not depending on accessing the complete data on the outset. Another important aspect is the presentation of query results. Due to its enormous size, a web query can retrieve thousands of resulting webpages. Thus meaningful methods for presenting these large results are
necessary to help a user to select the most interesting content.
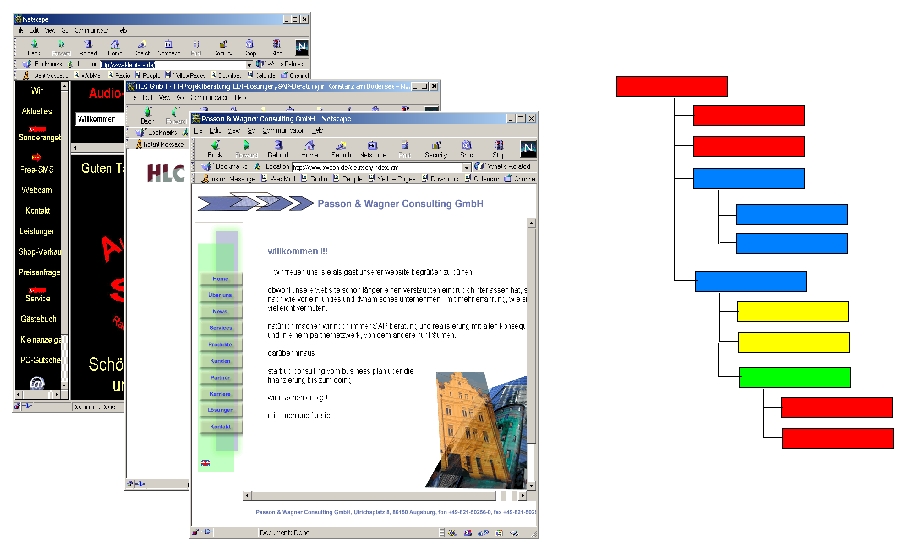
Classification of Multimedia Content and Websites
In order to retrieve relevant knowledge a system has to analyze web content first. Classification of web objects offers an automatic way to decide the relevance of web objects. Our focus in this area is the classification of websites or hosts. Since websites represent information on a more general level (e.g. a complete company) and are usually represented by multiple pages, classifiying website on top of webpage classification demands new algorithms.

Focused Crawling
A focused web crawler takes a set of well-selected web pages exemplifying the user interest. Searching for further relevant web pages, the focused crawler starts from the given pages and recursively explores the linked web pages. While the crawlers used for refreshing the indices of the web search engines perform a breadth-first search of the whole web, a focused crawler explores only a small portion of the web using a best-first search guided by the user interest.
We are especially interrested in crawling to retrieve complete websites, a task demanding new crawl strategies. Furthermore, we are interessted in crawling for multimedia content in the web, retrieving topics specific multimedia content instead of plain HTML documents.
Clustering Web Objects
Focused Crawling retrieves large numbers of relevant data. In order to offer fast and more specific access to the query results, clustering is an established method to group the retrieved information to achieve better understanding. If the query results are websites or combined objects like images and their text descriptions, new algorithm are needed to handle these combined data types to find meaningul clusterings.
Automatic Maintainance of Topic Specific Directory Services
Directory Services like DMOZ are an important method for WWW-users to locate interresting knowledge. Since general directory services try to handle all possible topics , the information provided for most topics is very incomplete. Thus, topic specific directory services are very useful to offer maximum information about web content treating this topic. To reduce the effort for maintaining a directory service, automatic classification, focused crawlers and clustering to present the provided content, helps to privde higher quality while demanding less manual interaction.
Bei Problemen oder Vorschlägen wenden Sie sich bitte an:
wwwmaster@dbs.informatik.uni-muenchen.de
Last Modified: